Our blog
How to Use Streamstats to Detect Anomalies in Splunk

Are you ready to take your Splunk skills to the next level? In the world of data analysis and cybersecurity, detecting anomalies is a game-changer. It can uncover hidden issues, security threats, and opportunities for optimization. And guess what? Splunk’s Streamstats can be your secret weapon in achieving this.
In this comprehensive guide, we’ll walk you through the process of using Streamstats to detect anomalies effectively in your Splunk environment. Whether you’re a seasoned Splunk pro or just starting your journey, this post is designed to equip you with the knowledge and skills to make the most out of this invaluable tool.
So, if you’re ready to supercharge your data analysis and security efforts, let’s dive in and explore how Streamstats can elevate your Splunk experience.
Understanding the Significance of Anomaly Detection
- Anomaly detection is a critical aspect of data analysis and cybersecurity.
- Detecting anomalies can uncover hidden issues and security threats.
- Streamstats in Splunk provides a powerful tool for achieving this.
What is Streamstats and Why Should You Use It?
- Streamstats is a feature in Splunk designed for real-time statistical analysis.
- It plays a crucial role in anomaly detection within Splunk.
- Learn why Streamstats is essential for your data analysis and security efforts.
Streamstats is a powerful feature in Splunk designed for real-time statistical analysis. It enables users to perform on-the-fly calculations and aggregations as data is ingested into Splunk. This means you can gain insights and detect anomalies in real-time, making it an essential tool for data analysis and cybersecurity.
Setting Up Streamstats in Splunk
-
To get started, you’ll need to set up Streamstats in your Splunk environment.
- Our step-by-step guide will walk you through the configuration process.
- Visual aids and code snippets will make the setup process clear and straightforward.
Setting up Streamstats in Splunk is a straightforward process that involves configuring the streamstats command in your Splunk searches. Here’s a simplified step-by-step guide to get you started:
-
Open Splunk and access the search bar.
-
Craft your search query or use an existing one.
- Add the streamstats command to your query, specifying the fields and calculations you want Streamstats to perform.
- Run the search, and Streamstats will start generating real-time statistics as data is processed.
- You can visualize the results using Splunk’s visualization tools or export them for further analysis.
Using Streamstats to Detect Anomalies
- Now that Streamstats is up and running, it’s time to put it to work.
- We’ll guide you through the steps of using Streamstats to identify anomalies in your data.
- Practical examples and use cases will illustrate the power of Streamstats in action.
Streamstats excels at detecting anomalies by continuously analyzing data streams and identifying deviations from established patterns. Let’s explore a practical example of how to use Streamstats for anomaly detection:
- Imagine you’re monitoring network traffic data in Splunk.
- You want to detect unusual spikes in data transfer volumes that could indicate a security breach.
- You craft a Streamstats query that calculates the moving average of data transfer volumes over a specific time window.
- You set a threshold for what constitutes an anomaly, based on historical data.
- When Streamstats detects data transfer volumes exceeding the threshold, it flags those instances as anomalies.
- You can then investigate these anomalies further to determine if they represent security threats or other issues.
Anomaly Detection Using Streamstats
The streamstats command in Splunk allows for real-time statistical analysis of data as it is ingested. It can be used to calculate moving averages, cumulative sums, and other statistics to detect anomalies.
Search Query (SPL):
index=testindex sourcetype=pan:traffic
| eval src_dest_pair=src.”|”.dest
| bin _time span=5m | stats sum(bytes_in) as bytes_in by _time src_dest_pair
| eval HourOfDay=strftime(_time,”%H”)
| sort 0 bytes_in
| streamstats current=f count as lower_bytes_count sum(bytes_in) as least_bytes_sum by src_dest_pair
| sort 0 -src_count
| streamstats current=f count as higher_bytes_count sum(bytes_in) as highest_bytes_sum by src_dest_pair
| eval count_of_nearby_values = higher_bytes_count+lower_bytes_count, sum_of_nearby_values=highest_bytes_sum+least_bytes_sum
| eval anomaly_score = (bytes_in*count_of_nearby_values)/sum_of_nearby_values
| where anomaly_score>5
| table _time, src_dest_pair, bytes_in, anomaly_score
The provided Search Query (SPL) calculates traffic-related statistics and employs streamstats to perform anomaly detection. It calculates the count and sum of nearby values for bytes_in based on the source-destination pair and evaluates an anomaly score. Rows with an anomaly score greater than 5 are considered anomalies, and only 20 such rows are returned. The anomaly score threshold can be adjusted based on specific requirements.
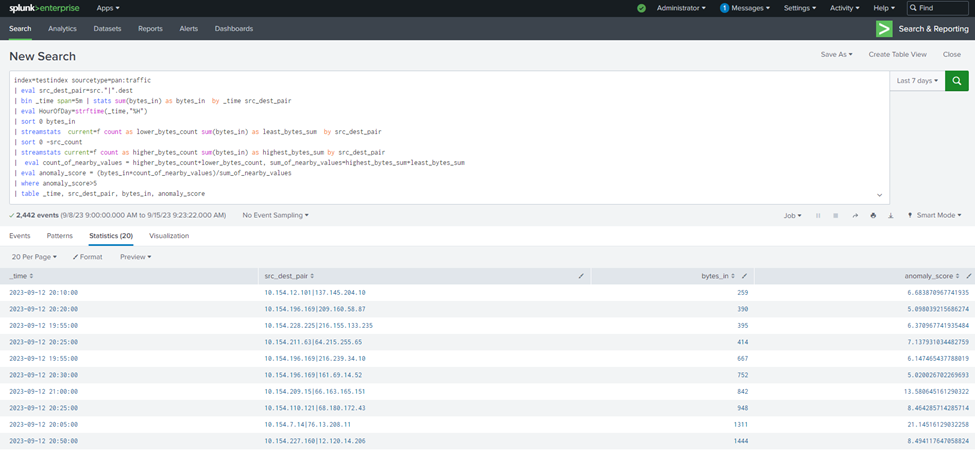
In our example, we’ve set a strict threshold to display only the most significant anomalies. However, Streamstats allows you to fine-tune this threshold according to your needs.
Streamstats Best Practices
- To get the most out of Streamstats, you’ll want to follow best practices.
- Our tips and recommendations will help you optimize your anomaly detection process.
- We’ll discuss common challenges and how to overcome them effectively.
To make the most of Streamstats for anomaly detection, consider these best practices:
- Optimize Your Query: Streamstats can be resource-intensive. Optimize your queries to reduce unnecessary calculations and improve performance.
- Set Appropriate Thresholds: Define clear anomaly thresholds based on historical data and the specific context of your analysis.
- Monitor Resource Usage: Keep an eye on resource consumption to ensure Streamstats doesn’t impact your Splunk environment’s performance.
- Regularly Review and Update: Periodically review and update your anomaly detection rules and thresholds to adapt to changing data patterns.
Common challenges in anomaly detection can vary depending on the specific context and dataset, but here are some general challenges and effective ways to overcome them:
| Sl. no | Challange | Solution |
|---|---|---|
| 1 | Imbalanced Data: Anomalies are often rare compared to normal data points, leading to imbalanced datasets. This can result in a model biased toward normal data. | Use techniques like oversampling, undersampling, or synthetic data generation to balance the dataset. Alternatively, employ anomaly detection algorithms designed for imbalanced data. |
| 2 | Feature Selection: Choosing the right features (variables) to detect anomalies can be challenging, as irrelevant or redundant features can lead to false positives. | Conduct feature engineering to select relevant features and reduce dimensionality. Utilize domain knowledge to identify informative attributes. |
| 3 | Model Selection: Selecting the appropriate anomaly detection algorithm or model for a given dataset can be tricky. | Experiment with various algorithms (e.g., statistical, machine learning, or deep learning) and evaluate their performance using appropriate metrics. |
| 4 | Threshold Setting: Determining the anomaly score threshold for classification can be subjective and may impact the number of false positives and false negatives. | Use techniques like cross-validation to optimize the threshold. Consider the business impact of false positives and negatives when setting the threshold. |
| 5 | Time Series Anomalies: Detecting anomalies in time series data can be challenging due to seasonality and trend variations. | Apply time series-specific anomaly detection methods, such as moving averages, exponential smoothing, or LSTM-based models. |
| 6 | Scalability: As datasets grow, scalability becomes an issue for some anomaly detection methods. | Utilize distributed computing frameworks or cloud-based solutions to handle large datasets efficiently. |
| 7 | Labeling Anomalies: In some cases, labeling anomalies for supervised learning can be difficult or costly. | Consider semi-supervised or unsupervised anomaly detection techniques that don’t require labeled anomalies. |
| 8 | False Positives: Anomaly detection models may generate false positives, leading to unnecessary alerts or actions. | Fine-tune models to reduce false positives, and implement post-processing techniques to filter out noisy alerts. |
| 9 | Concept Drift: Over time, data distributions may change, making previously trained models less effective. | Solution: Continuously monitor and retrain models to adapt to evolving data distributions. |
| 10 | Interpretable Models: Understanding why a model flagged a particular instance as an anomaly is important for trust and decision-making. | Use interpretable models or techniques that provide feature importance scores or explanations. |
Real-World Applications
Streamstats has found application in various real-world scenarios, including:
- Network Security: Detecting unusual network traffic patterns that could indicate cyberattacks.
- IT Operations: Monitoring server performance and identifying performance anomalies.
- Financial Analysis: Detecting fraudulent transactions by identifying unusual financial activity.
- Healthcare: Monitoring patient data for unusual trends that may require medical attention.
- Industrial IoT: Identifying anomalies in sensor data to prevent equipment failures.
Anomaly Detection Using Splunk by Other Methods.
a. InterQuartile Range (IQR)
The InterQuartile Range (IQR) method is used to identify outliers or anomalies in data. It involves calculating the IQR, which is the range between the first quartile (25th percentile) and the third quartile (75th percentile) of the data. Values that fall below the lower bound or above the upper bound are considered outliers.
Check the link for more information
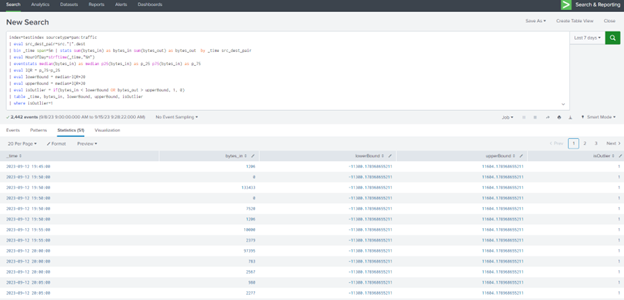
Search Query (SPL)
index=testindex sourcetype=pan:traffic
| eval src_dest_pair=src.”|”.dest
| bin _time span=5m | stats sum(bytes_in) as bytes_in sum(bytes_out) as bytes_out by _time src_dest_pair
| eval HourOfDay=strftime(_time,”%H”)
The provided Search Query (SPL) is designed to calculate traffic-related statistics, including the sum of incoming and outgoing bytes for each unique source-destination pair within a 5-minute time span. It also evaluates the hour of the day when the data was recorded. The query then returns 51 results, which may include data points that deviate significantly from the norm.
b. Machine Learning Tool Kit (MLTK) app
The Machine Learning Tool Kit (MLTK) app in Splunk provides machine learning capabilities for anomaly detection. It uses statistical models to identify anomalies in data based on patterns and deviations from the expected behavior.
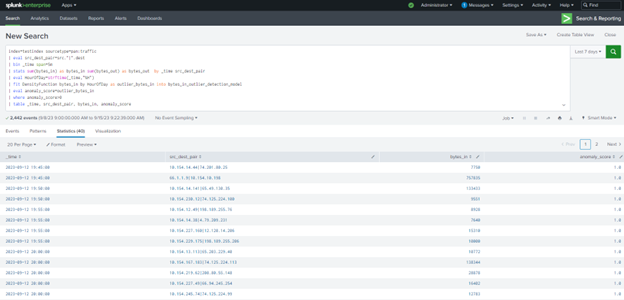
Search Query (SPL)
index=testindex sourcetype=pan:traffic
| eval src_dest_pair=src.”|”.dest
| bin _time span=5m
| stats sum(bytes_in) as bytes_in sum(bytes_out) as bytes_out by _time src_dest_pair
| eval HourOfDay=strftime(_time,”%H”)
| fit DensityFunction bytes_in by HourOfDay as outlier_bytes_in into bytes_in_outlier_detection_model
| eval anomaly_score=outlier_bytes_in
| where anomaly_score>0
| table _time, src_dest_pair, bytes_in, anomaly_score
The provided Search Query (SPL) is similar to the previous method but incorporates MLTK. It calculates traffic-related statistics, including the sum of incoming and outgoing bytes, evaluates the hour of the day, and then uses MLTK to fit a density function to the incoming bytes data. An anomaly score is computed, and only results with a positive anomaly score (indicating outliers) are displayed. The query returns 40 results that are considered anomalies.
Each of these methods has its strengths and may be more suitable for different use cases. The choice of method depends on factors such as the type of data, the desired level of accuracy, and the ease of implementation.
However, Streamstats finely filter anomalies based on predefined criteria. It provides the flexibility to adjust the anomaly score threshold, allowing you to control the sensitivity of your anomaly detection. Whether you prefer high precision or a broader view of anomalies, Streamstats empowers you to tailor your anomaly detection strategy for optimal results. This flexibility allows users to fine-tune the anomaly detection based on their specific requirements and tolerance for false positives.
Search Here
Latest Posts

